TXT Chapter Splitting (Regular Expressions)
Why Split TXT
TXT is a plain text format that does not inherently include chapter information. If imported directly, some features within the application (like chapter navigation) may not work properly.
From both a design and user perspective, performing a simple chapter split before importing helps enhance the subsequent reading experience.
How to Split
Rodel Reader uses regular expressions to match characteristic chapter titles. Every time a title matching the pattern is found, a split is made, thus dividing the entire book.
Afterwards, the entire TXT file is split and combined according to predefined rules to form an EPUB file, which is then imported into the library. Therefore, what you read later is not the original TXT but this EPUB file.
If you have some basic knowledge of regular expressions, chapter splitting will be much easier for you.
If you don't know anything about regular expressions, no worries. Thanks to AI advancements, you can query any LLM to get a regular expression. For specific operations, see AI Generating Regular Expressions.
Built-in Rules
To simplify operations, Rodel Reader includes some basic chapter matching rules (which will be continuously improved):
- Chinese Chapters:
Expression:^(第)([―-\-─—壹贰叁肆伍陆柒捌玖一二两三四五六七八九十○零百千O0-90-9]{1,12})([章节節回集卷部篇])(.*)
Description: This expression is suitable for matching common chapter-style titles, supporting the vast majority of online literature and traditional Chinese novels. - Numbered Chapters:
Expression:^\d+\s*[\.\)\-\–\—\、\。\,\;]*[\s\u3000]*.+
Description: This expression can match formats likeNumber+Punctuation+Chapter Name, for example,1. xxxxxx - English Chapters:
Expression:[Cc]hapter\s+(\d+|[IVXLCDM]+)(.*)
Description: This expression is mainly used for matching standard English chapter titles, such asChapter 1 xxxxxx
Custom Rules
The built-in rules obviously cannot handle all situations, so you may need to write your own regular expressions if necessary.
You can view basic regular expression rules at Regular Expression - Syntax. This document focuses on the process with a simple example:
- Use Notepad or another text editor to open the book you want to import (e.g., "Harry Potter")
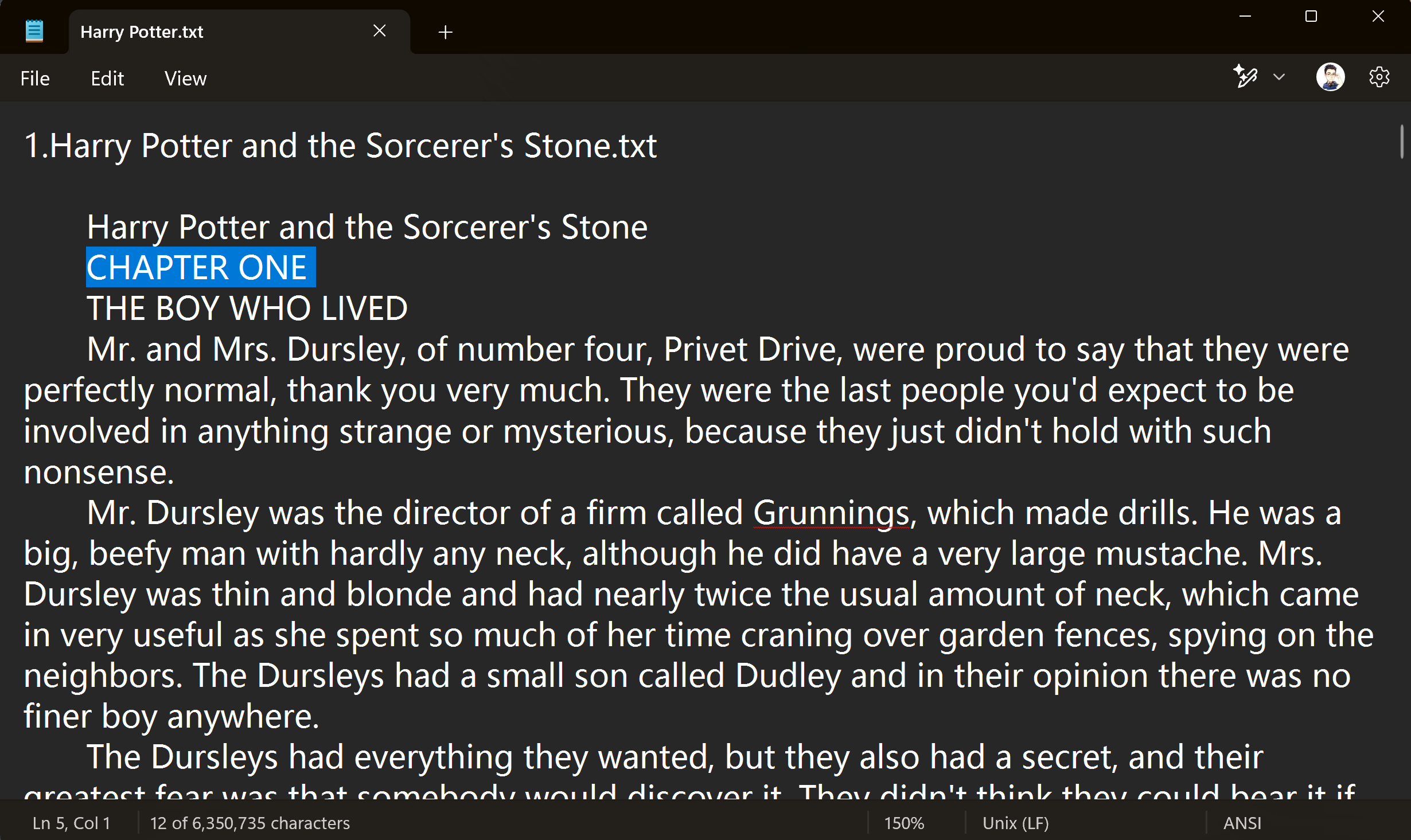
We can see that its chapter title structure isCHAPTER xxx - Write a simple expression based on the chapter characteristics
We can replace the specific chapter number and title with placeholders.*, which is a simple matching pattern.
This gives us an expression like:CHAPTER\s(.*)
where\srepresents a space. - Input it in the APP to verify the result
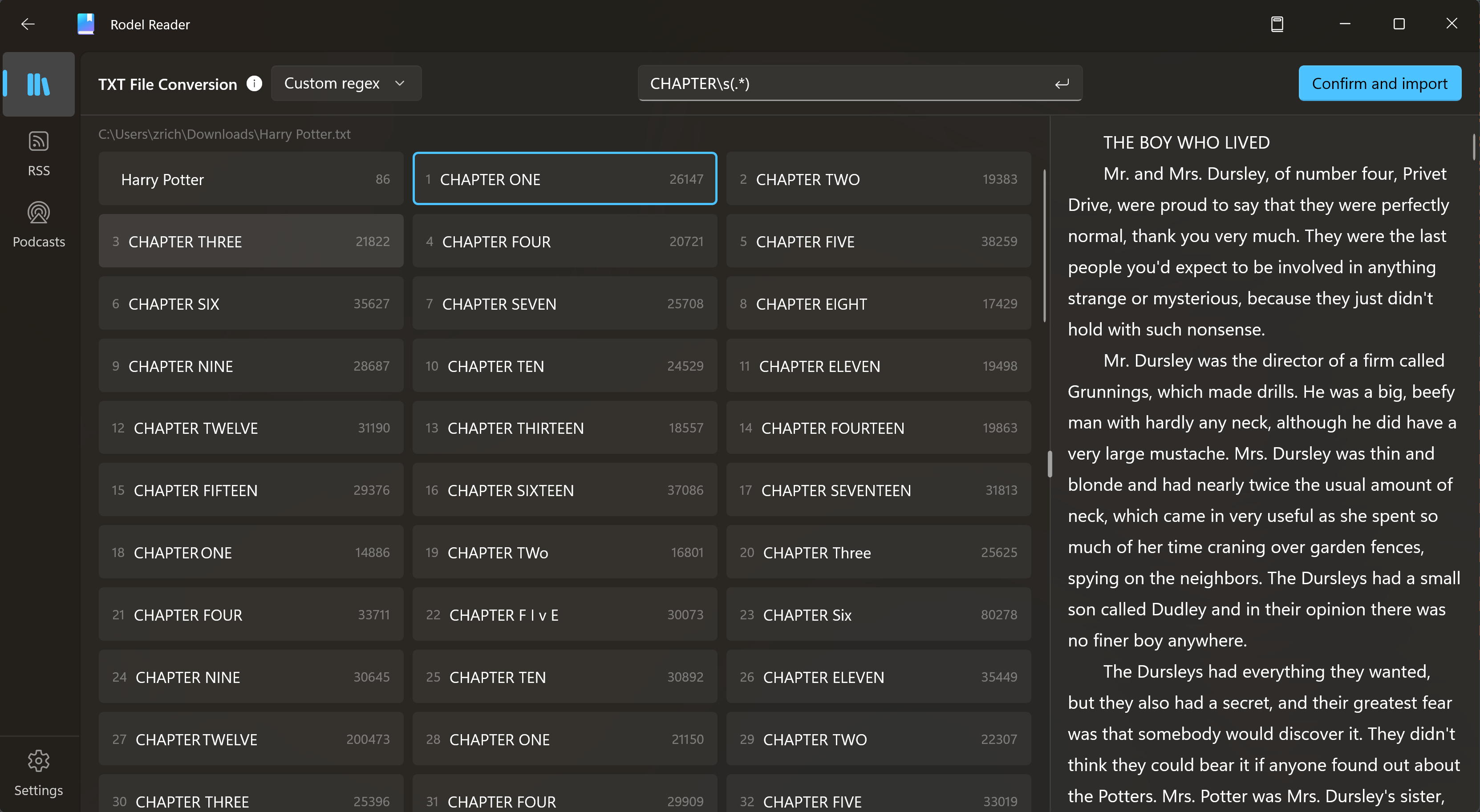
From the result, our expression is correct, and it helps us properly split all the chapters.
AI Generating Regular Expressions
Now with AI, you can use regular expressions to split TXT novels like a pro even without understanding the rules of regular expressions.
Use your preferred AI service, modify the following prompt based on your actual situation, and give it to the AI.
TIP
If the regular expression result returned by AI is not as expected, try providing more chapter titles so that AI can better identify the title pattern.
Generate a regular expression that can be used in C# based on the following titles (only the expression, no code needed) to match similarly structured chapter titles, no grouping required, keep it as simple as possible:
```
{Your chapter title}
```For example, for the above example of "Harry Potter", the modified prompt would be:
Generate a regular expression that can be used in C# based on the following titles (only the expression, no code needed) to match similarly structured chapter titles, no grouping required, keep it as simple as possible:
```
CHAPTER ONE
```Give it to OpenAI, and its response would be:
^CHAPTER [A-Z]+$Plug it into the APP and try it out, no problem.