TXT 章节分割(正则表达式)
为什么要切分 TXT
TXT 是一种纯文本格式,本身不包含章节信息,如果直接导入,会使得应用内一些功能(比如章节跳转)无法使用。
所以无论是从设计角度还是用户角度,在导入前进行一次简单的章节切分,都有助于提高后续的阅读体验。
如何拆分
小幻阅读采用 正则表达式 来匹配具有特征的章节标题,每次匹配到相应的标题内容就做一次切割,以此来完成整本书的拆分。
之后,整个 TXT 会按照既定规则拆分并组合成一个 epub 文件,然后导入到书库之中,后续你阅读的并不是原始的 TXT,而是这个 epub 文件。
所以,如果你具备一定的正则表达式基础知识,那么章节拆分对你来说会容易很多。
如果你完全不了解正则表达式,也没关系,得益于 AI 的发展,你可以在任意LLM中提问,来获取一个正则表达式,具体操作请见 AI生成正则表达式。
内置规则
为了简化操作,小幻阅读内置了一些基础的章节匹配规则(后续会不断完善):
- 中文章节:
表达式:^(第)([―-\-─—壹贰叁肆伍陆柒捌玖一二两三四五六七八九十○零百千O0-90-9]{1,12})([章节節回集卷部篇])(.*)
说明:这个表达式适合匹配常见的章回体标题,支持绝大多数网文和传统中文小说。 - 序号章节:
表达式:^\d+\s*[\.\)\-\–\—\、\。\,\;]*[\s\u3000]*.+
说明:这个表达式可以匹配类似数字+标点+章节名的格式,比如1. xxxxxx - 英文章节:
表达式:[Cc]hapter\s+(\d+|[IVXLCDM]+)(.*)
说明:这个表达式主要用于匹配英文标准章节名称,类似Chapter 1 xxxxxx
自定义规则
内置的规则显然不能处理所有情况,必要时你需要自己编写正则表达式。
基础的正则表达式规则你可以在 正则表达式 - 语法 中查看,这里不做过多介绍,仅举例说明流程:
- 使用 Notepad 或者其它能打开 txt 的编辑器打开你要导入的书籍(以《三国演义》举例)
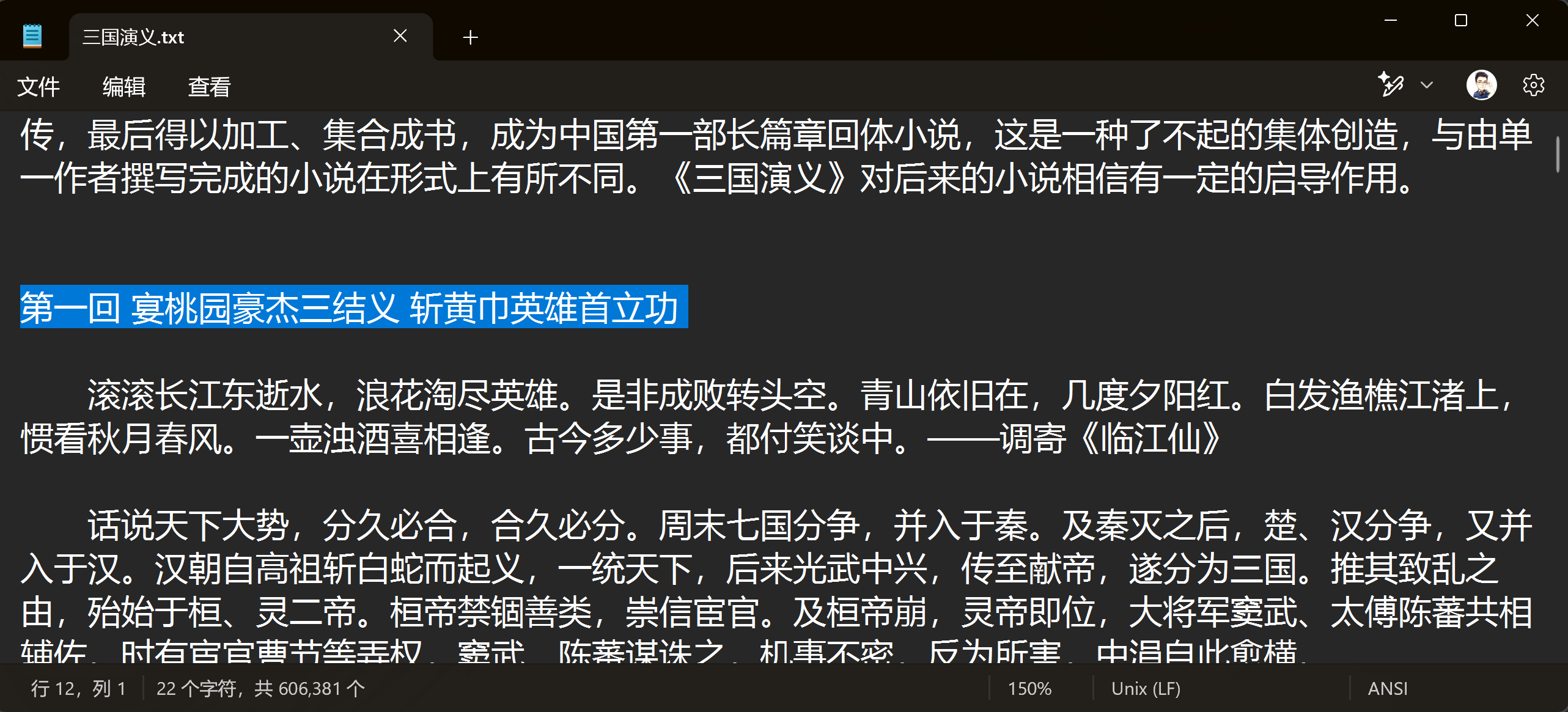
我们可以观察出来,它的章节标题结构是第x回 xxxxxxxxx - 根据章节特征,书写简单的表达式
我们可以将具体的章节序号和标题换成占位符.*,这是一种简单的匹配模式。
这样我们就可以得到如下表达式:第(.*)回\s(.*)
其中,\s表示一个空格 - 在 APP 内输入以验证结果
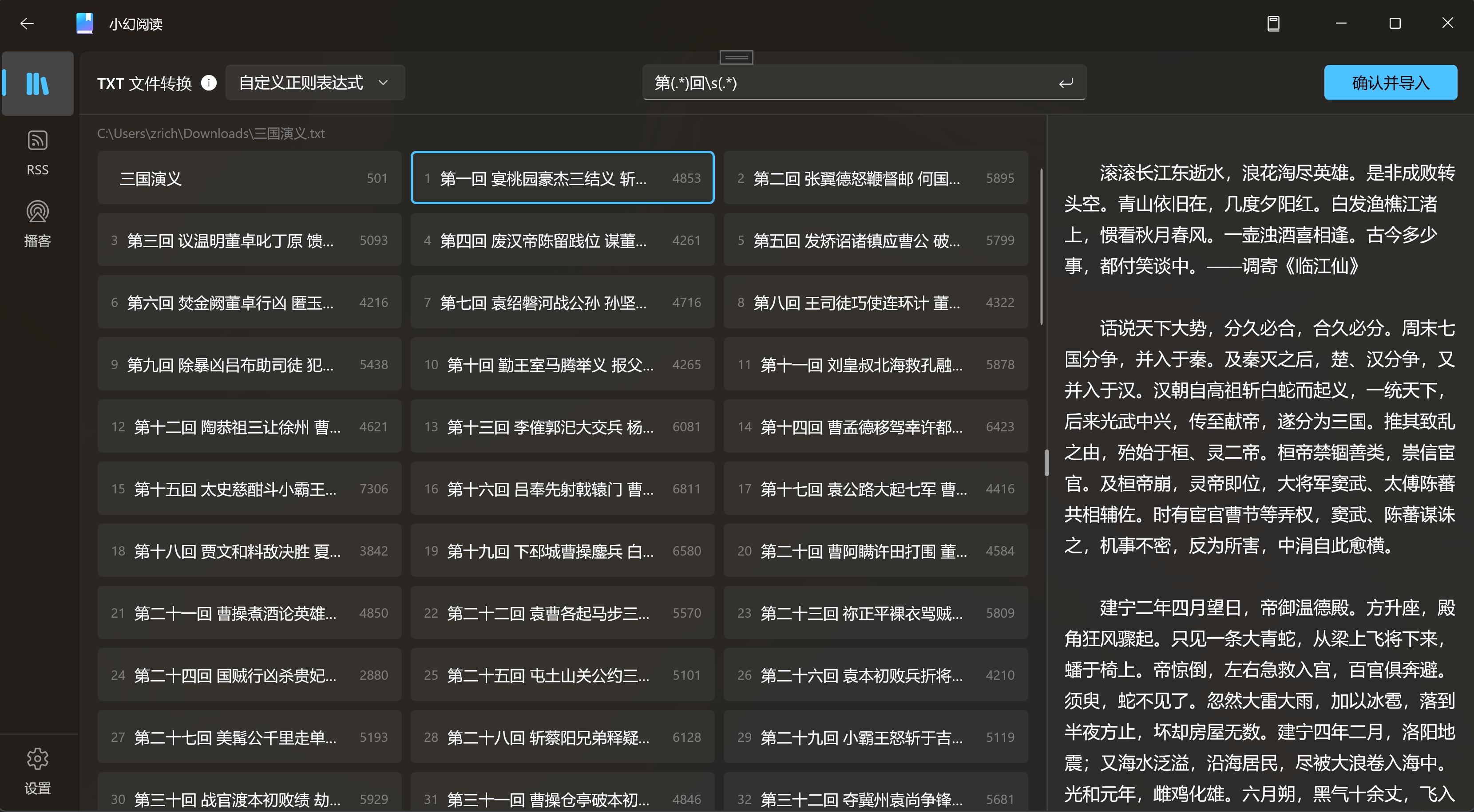
从结果来看,我们的表达式没毛病,它可以帮助我们正确拆分所有章节。
AI生成正则表达式
现在有了 AI,你可以在完全不了解正则表达式的规则的情况下像一个高手一样使用正则来拆分 TXT 小说了。
使用你习惯的 AI 服务,将下面的提示词根据实际情况修改后丢给 AI 即可。
TIP
如果 AI 返回的表达式结果并不符合预期,可以尝试多传入几个章节标题,这样 AI 可以更好地发现标题规律。
markdown
根据下面的标题内容,生成一个可以被 C# 使用的正则表达式(只要表达式,不需要代码),以此匹配类似结构的章节标题,不需要分组,尽量简洁:
```
{你的章节标题}
```比如上面的《三国演义》的例子,修改后的提示词如下:
markdown
根据下面的标题内容,生成一个可以被 C# 使用的正则表达式(只要表达式,不需要代码),以此匹配类似结构的章节标题,不需要分组,尽量简洁:
```
第一回 宴桃园豪杰三结义 斩黄巾英雄首立功
```丢给 OpenAI,它的回复就是:
plaintext
^第[一二三四五六七八九十百千万]+回 .+ .+$代入 APP 中试一试,没问题。